介绍横纵向爬取
横纵向爬取用一句话就能说明白:
例如去房地产网站爬房子,在目录页按页爬下房子详情页链接的过程是横向爬取,更进一层爬详情页中的信息如房价地段等的过程是纵向爬取。
介绍 Scrapy 爬虫框架
Scrapy 爬虫框架怎么解决横纵向爬取
以下是 Scrapy 首页第一个例子,一个博客爬虫: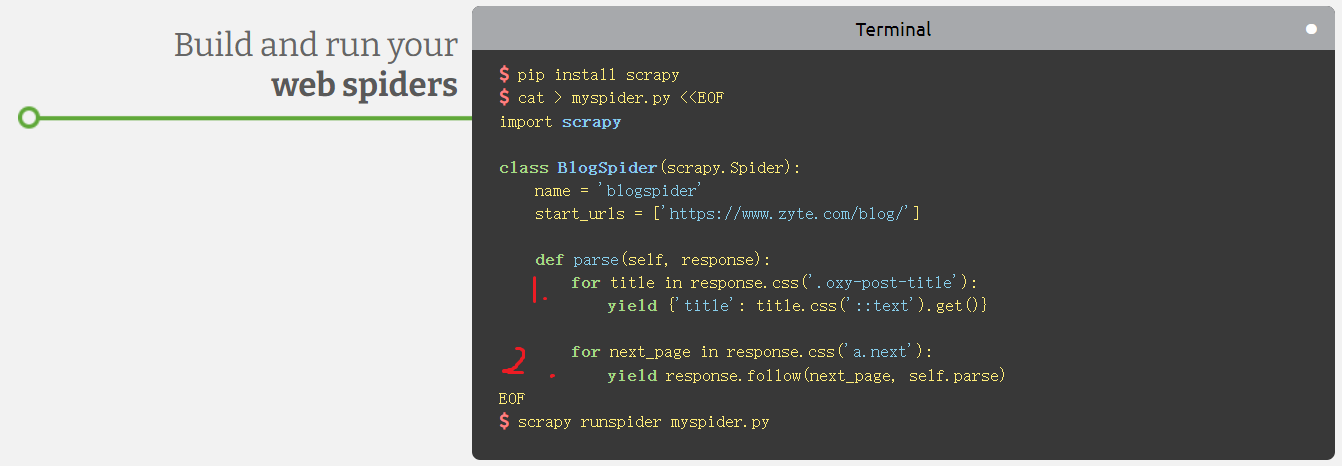
序号1的部分代码,Spider 返回 dict 表示纵向爬取到底获取到最终信息了。
序号2的部分代码,Spider 调用一个特殊函数,表示还要继续横向爬取。
结合 Scrapy 爬虫框架底层引擎架构。我们来理解下 Scrapy。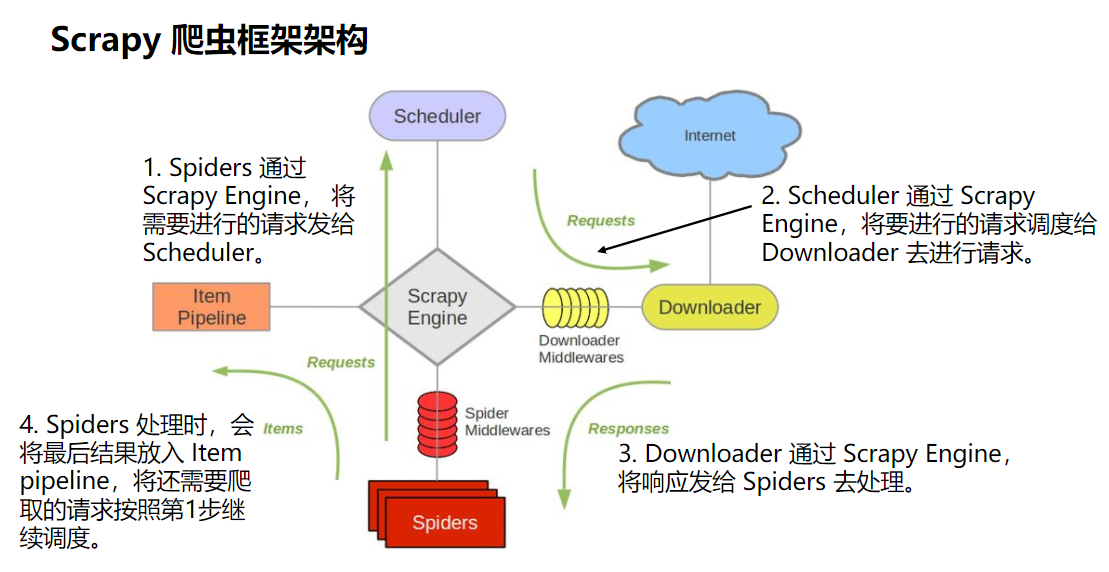
还是爬房地产网站的例子。在房地产网站目录页爬到上图第4步时 Spider 就会把详情页链接继续往 Scheduler 去放,让 Scheduler 这个 consumer 饱和工作。而在详情页就会把最终结果往 Item Pipeline 去放
Scrapy 爬虫框架解决了什么问题
我认为最重要的是以下三点:
- 不用结合自己找各种解析器和选择器了。HTML、XML,JSON解析,CSS选择器等等一应俱全,
- 可以方便的调节爬取速率,Spider 表现等。
- 提供了一套 CLI 工具用于监控,调试。
当然,没解决的问题也有:反爬,IP限制…
介绍 Zyte:爬虫 as a Service
Zyte 的前身叫做 ScrapingHub,这家公司维护了 Scrapy 这个爬虫框架。于是我们可以看到 Scrapy 中许多特性与 Zyte 有关: 一键部署爬虫到 Zyte,Zyte 上可以监控爬虫、定时爬取……
当然,仅仅只提供部署服务的话,这家公司可能完全没有竞争力。作为一个 SaaS平台,他们有两个另外的服务,让我愿称它的 SaaS 为 Spider as a Service。这个服务就是,自动代理和自动结构化提取网站内容。
第一个功能叫做自动代理。不多赘述,其实就是一个给你的爬虫用的 ip 池,这个服务的杀手级还不够强。
自动结构化提取网站内容是一个杀手级功能,这个功能以 API 形式提供:
下图是典型的豆瓣小组目录页和小组。
如果你用我之前提到的方法开始横纵向爬取,然后你就会遇到频次限制,IP 限制,未登录限制,验证码限制…
但如果你使用 Zyte 的服务,只要你先调用 Article List Extraction API 横向爬取每个目录页,再批量对文章链接调用 Article List API 信息, Zyte 就能提取出来并自动识别文章页面上的每项信息如作者,发文时间,正文内容,评论作者/内容…,最后转换成json,格式类似如下:
{
"topic": {
"articleBody": "我上上赛季低星王者,胜率大概57% 左右\n\n中野射上单都玩 就是不太会玩辅助\n\n上个赛季恶心死我了,我记得打了快两百场胜率48%这样,靠积分苟上星耀...",
"headline": "只要忍住一个月以上不玩,排位就会很容易!",
"inLanguage": "zh",
"datePublished": "2021-04-21T21:50:29",
"datePublishedRaw": "2021-04-21 21:50:29",
"author": "karen酱",
"authorsList": ["karen酱"],
"mainImage": "https://img9.doubanio.com/icon/u181208014-2.jpg",
"description": "上个赛季恶心死我了,我记得打了快两百场胜率48%这样,靠积分苟上星耀,当时都要被这个游戏气哭了,下班后熬夜打也输,玩啥位置都输,擅长的英雄也输! ! !",
"url": "https://www.douban.com/group/topic/222195435/",
},
"author": {
"text": "...",
"href": "..."
}
}
我第一次用完这个功能之后,看着返回给我的整齐的 JSON,想起之前处理反爬的窘况,我突然感觉手写爬虫这件事变得无比的笨。毕竟,反爬这件事是不可避免的,就算你经验怎么丰富,也写不出反爬框架节约自己的时间。
那么这项服务的价格是多少呢?这项功能以 API 形式提供,在我写这篇文章时,服务的 API 调用价格是 $60/10万 次请求。充值之后只需要下载一个 SDK,你就不用处理任何反爬或者是IP池的恶心事,如果是经得住爬的网站,那么结果返回的速度飞快,约等于花钱买爬虫结果+节约的时间。
总结和声明
最后声明,本文不是 Zyte 的软文。因为 Zyte 在本文写作时还没有任何邀请优惠计划,并且我也没放什么邀请链接之类的。那么我是怎么试用到这个公司的产品呢?因为 Github 学生包提供了10万个请求,于是我就试了一下,发现确实好用。所以说这也给我了一个商业上的启发,就是在学生时期培养消费习惯确实是有效的。
展望
这篇应该是完结篇了。我认为爬虫在中国的法律风险实在太大,我在上篇文章最开头就描述了自己根本不想爬虫的心情。但是我认为这些经验级知识落到笔下还是有好处的。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以邮件至 [email protected]